
智象未来全新编辑框架VAREdit,0.7秒实现精准图像编辑
时间:2025-08-27 20:51来源:中国企业报看安徽 作者:彭学英/吴明张骅
本报记者 彭学英/吴明 张骅 前言 近年来,强大的扩散模型(DiffusionModel)席卷了AI图像编辑领域,它们能生成惊艳且逼真的图像。然而,这背后却隐藏着两大痛点:效果失控与效率低下。由于其牵一发而动全身的生成机制,尽管只想修改一个局部细节时,模型却可能画蛇添足,影响到本应保持不变的区域,导致编辑不精准。同时,漫长的迭代过程也让即时编辑成了一种奢望。 为
本报记者 彭学英/吴明 张骅

前言
近年来,强大的扩散模型(DiffusionModel)席卷了AI图像编辑领域,它们能生成惊艳且逼真的图像。然而,这背后却隐藏着两大痛点:效果“失控”与效率低下。由于其“牵一发而动全身”的生成机制,尽管只想修改一个局部细节时,模型却可能“画蛇添足”,影响到本应保持不变的区域,导致编辑不精准。同时,漫长的迭代过程也让“即时编辑”成了一种奢望。

为攻克这些难题,智象未来团队开辟了一条新路径:将视觉自回归(VAR)架构引入图像编辑。我们提出了全新的指令引导编辑框架VAREdit,它精准地解决了扩散模型的固有顽疾。VAREdit能够做到“指哪打哪”,在严格遵循指令、提升编辑质量的同时,将生成效率推向了新的高度,实现了精准度与速度的双重突破。
模型与代码均已开源:
·GitHub:https://github.com/HiDream-ai/VAREdit
·在线使用:https://huggingface.co/spaces/HiDream-ai/VAREdit-8B-1024
研究背景与动机
近年来,高质量编辑数据集以及高效扩散去噪架构的发展,为指令引导的图像编辑领域带来了长足进步。得益于扩散架构的全局迭代去噪过程,所生成的编辑图像展现出强大的视觉保真度。然而,这一核心过程的固有缺陷也为指令引导的图像编辑带来了重大挑战:
·编辑效果受限:去噪过程的全局特性使得局部编辑指令不可避免地会对全局图像结构产生影响,其编辑过程容易渗透到本应保持不变的区域,使得局部编辑与全局结构产生非预期的耦合现象,导致虚假或不完全的编辑。
·编辑速度缓慢:扩散模型依赖于多步迭代去噪来生成目标图像,这一过程需要大量的计算资源与开销,导致编辑耗时较长,严重阻碍了该技术在需要即时反馈的实时应用场景中的部署。
相比之下,自回归(AR)模型采用顺序因果逐标记视觉令牌预测的方式进行图像生成。这种组合生成过程提供了一种灵活的机制,可以在精确修改编辑区域的同时保留未更改的区域,以解决扩散模型中的区域耦合问题。然而,基于传统自回归建模的图像编辑模型仍然存在难以捕捉全局结构、采样效率低下的问题。
方法概览
主体架构
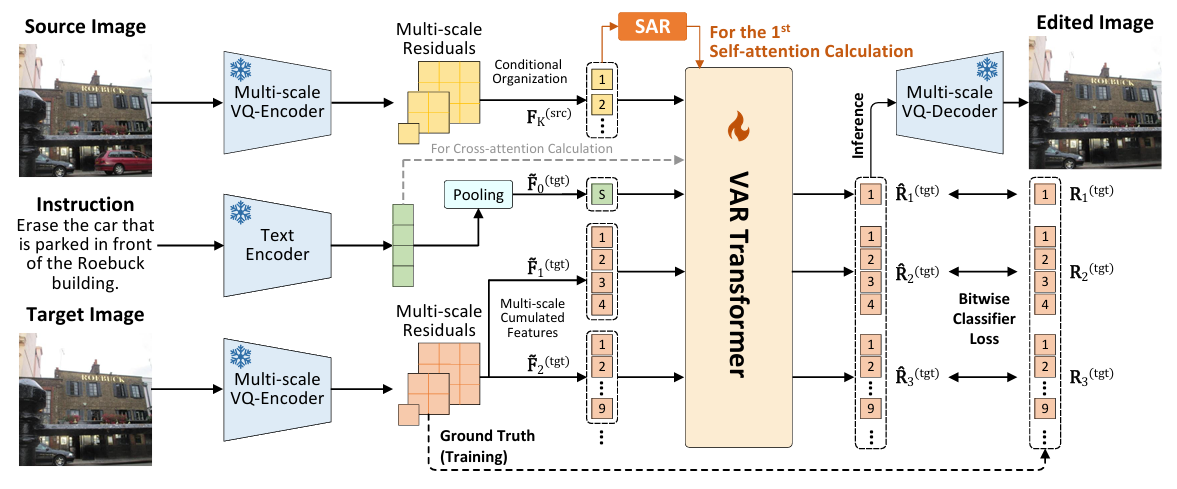
本工作提出的VAREdit将视觉自回归建模引入指令引导的图像编辑中,将图像编辑定义为下一尺度预测问题,通过自回归地生成下一尺度目标特征残差,以实现精确的图像编辑。
·多尺度量化编码:将图像表征编码为多尺度残差视觉令牌序列,其中的空间规模随着的增大而依次递增;融合前个尺度残差信息的连续累积特征可通过码本查询和上采样操作进行加和,表示为。
·视觉自回归预测:基于源图像和文本指令条件,使用VARTransformer主干网络对目标图像的多尺度残差视觉令牌序列进行预测,其概率函数为。其中,主干网络预测对应输入的视觉连续特征为经空间规模下采样对齐的融合特征。
条件组织
设计VAREdit的一个核心挑战是如何将源图像信息引入主干网络中,作为目标尺度生成的参考信息。本工作首先探索了两种组织方案:
·全尺度条件:将源图像的所有尺度融合特征作为主干网络输入连续特征前缀。该方法为编辑任务提供了全面的、逐个尺度的参考,但序列长度加倍会导致自注意力成本呈二次方增长,使其不适用于高分辨率编辑。此外,提供多个源尺度特征可能会为预测单尺度目标特征带来冗余或冲突的信息,从而可能降低编辑质量。
·最大尺度条件:将源图像的最大尺度融合特征作为主干网络输入连续特征前缀。虽然这种策略显著缩短了序列长度以缓解计算瓶颈,但它也带来了一个关键的尺度不匹配挑战。若仅提供最细粒度的源图像参考,模型可能难以在预测目标尺度时进行较好的尺度适应,尤其是在预测粗粒度目标尺度残差的情形下。

本工作进一步对在全尺度条件所训练模型中的自注意力机制进行了诊断分析,可以看到:
·在第一个自注意力层中,注意力机制分布广泛,主要集中在相应的以及所有较粗的源尺度上。这种模式表明,初始层负责建立全局布局和长程依赖关系。
·在更深的自注意力层中,注意力模式变得高度局部化。它们表现出强烈的对角结构,表明注意力主要局限于空间邻域内的标记。这种功能转变表明,注意力从全局构建转向局部细化。
尺度对齐参考
上述探索促使本工作设计一种混合解决方案,即尺度对齐参考(SAR)模块,在第一层提供尺度对齐的参考,而所有后续层仅关注最细尺度的源。具体来说,在最大尺度条件模型中,将第一个自注意力层中的源图像条件输入进行各尺度匹配的下采样操作,得到对应尺度的参考特征。随后,在计算第个目标尺度对应的自注意力表示时,由替代参与Key和Value的计算即可。通过上述SAR模块优化,使得VAREdit能够更好地捕捉源图像与目标图像之间的多尺度依赖关系,同时实现最大尺度条件模型的生成效率。
实验结果
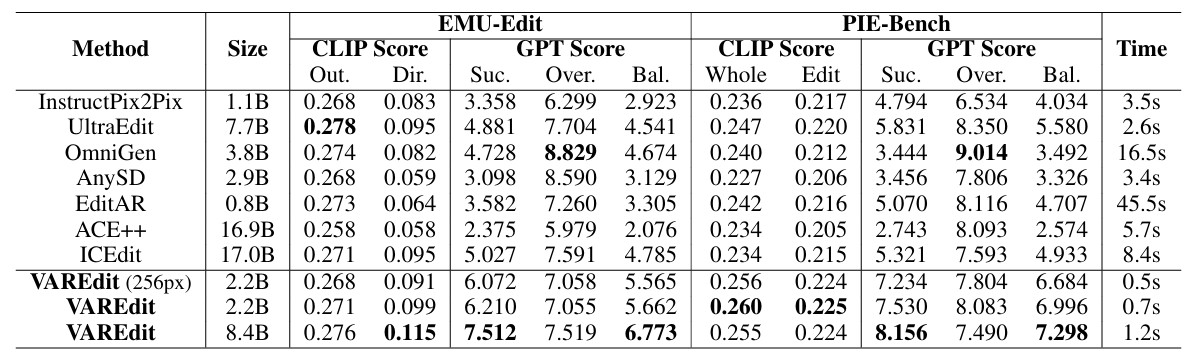
·定量指标领先:在EMU-Edit和PIE-Bench这两个业界公认的基准测试数据集上,VAREdit在传统的CLIP的评价指标和更能体现编辑精准性的GPT指标均取得了显著优势。特别地,VAREdit-8.4B模型在这两个数据集的GPT-Balance指标上,相较于具有强竞争力的扩散架构方法ICEdit和UltraEdit分别提升了41.5%和30.8%。此外,较小的VAREdit-2.2B相较于过往方法也依然具有较为显著的效果提升。
·编辑速度飞快:VAREdit在大幅提升图像编辑精准性的同时,保持了极高的生成速度。得益于视觉自回归的下一尺度预测范式,VAREdit-8.4B可以在1.2秒内编辑一张512×512分辨率的图像,相比近似规模的扩散编辑模型UltraEdit快2.2倍。此外,较小的VAREdit-2.2B的编辑所需时间仅需0.7秒,但相较于过往方法仍然有较为领先的图像编辑质量。
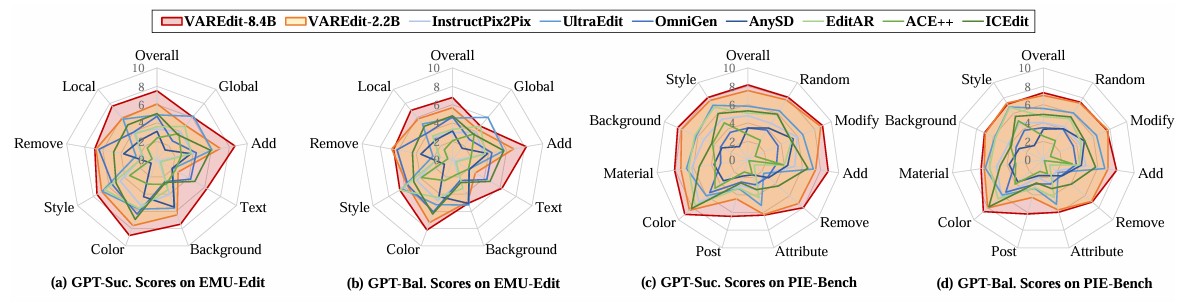
·适用种类广泛:在不同编辑类型上的测试结果显示,VAREdit在绝大多数编辑类别上都达到了最佳性能。虽然2.2B模型在具有挑战性的全局样式和文本编辑任务中表现出一些局限性,但8.4B模型大大弥补了这一性能差距。这体现了VAREdit卓越的扩展性能,通过扩展到更大的模型和数据集,可以使编辑性能得到进一步提升。

·定型效果优异:从视觉效果对比图可以清晰地看到VAREdit的强大图像编辑能力。相较于过往基于扩散模型的编辑架构,VAREdit拥有更强的编辑精准性,具体表现在指令执行更加成功,过度编辑的影响更小,编辑得到的图像高度保真且观感自然。
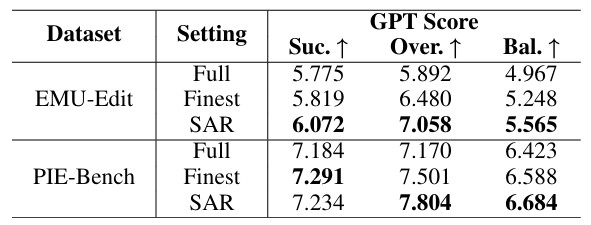
·SAR模块提升:对比原始的全尺度条件、最大尺度条件模型和经过SAR模块优化的模型,可以看到SAR增强模型具有更高的GPT-Balance分数,体现出尺度匹配信息注入为图像编辑的精准性带来了较为有效的提升。
结语
本工作提出的VAREdit将新颖的下一尺度预测范式引入指令引导的图像编辑框架,基于文本指令和量化的源图像特征预测目标图像的多尺度视觉残差,通过分析不同条件组织形式的有效性并提出新颖的SAR模块,实现了图像编辑在精准性和高效性的双重提升。未来,智象未来团队将持续探索下一代多模态图像编辑模型架构,致力于实现更高质量、更快速度、更强可控性的指令引导图像编辑与视觉生成技术。
相关文章
- 05-23祁南矿掀起“两学一做”学习热潮
- 02-29合肥市党员志愿者全天值守保障群众生命健康
- 04-03洛河发电厂节前安全生产管控紧锣密鼓
- 09-29合肥经开区消防设施操作技能人才齐聚“大比武
- 01-20中煤新集地勘公司定向钻进技术研究取得新进展
- 01-17中铁四局某项目部临建施工与征地拆迁双推进
- 02-06合肥市瑶海区城管扫雪除冰保交通畅通
- 05-31合肥市高新区两淮海棠小区率先实现加装电梯全
- 03-13郑孝和:振兴徽茶应从喝“功夫绿茶”开始
- 08-20淮北矿业铁运处临涣电务段“零点行动”为安全